德州扑克在线规则点击下图进入官网:

德州扑克在线规则点击下图进入活动:

德州扑克在线规则点击下图进入领取彩金:

优乐国际|http://ylgjoxqy.weebly.com
万博客户端|http://wbkhdfkok.weebly.com
伟易博官网|http://wybgwrtnf.weebly.com
优发国际娱乐|http://yfgjylcrrg.weebly.com
澳门老虎机网站|http://amlhjwztjvt.weebly.com
99真人|http://zrjypd.weebly.com
初步研究地球的任务。显然,人工智能已经提前知道将面临新任务比神经网络可以执行的新发展更好,更快的训练。也许可以DeepMind PathNet实现这一目标。

PathNet是一个网络的神经网络,神经网络的网络),通过随机梯度下降法和基因选择方法进行训练。PathNet层组成的模块,每个模块可以是一个,任何类型的卷积神经网络可以循环网络,前馈网络,等等。图1:一个随机初始化的路径(紫线)图1学习任务中设置一个乒乓球比赛在进化的过程中。
训练结束的时候,最好的路径是固定的(图5中的红线),并将有一个新的路径任务B(浅蓝色线)在图5中生成。路径设置和获取培训外星人的游戏,然后逐渐演变在这陌生的游戏,固定的训练来达到最好的路径,如图9所示的深蓝色的线。九PathNet框图是在不同的迭代。
在这种情况下,PathNet优势通过训练演员——评论家(A3C)两种不同的游戏去玩
虽然乒乓球和外星人看起来非常不同的,但我们确实观察(见图)一个用PathNet迁移研究。如何训练它。首先,我们需要定义模块。设置的层数L,N是模块每一层的最大数量(论文表明,N是通常3或4)。
最后一层是致密的,而不是在不同的任务之间共享。通过A3C表示,最后一层值函数(价值函数)和战略评价(政策评估)。该模块定义后,网络一代P基因型(=路径)。由于A3C的异步性质,需要更多的工作,每个基因型(工人)的评估。
T一集后的工作从其他路径比较,如果有更好的适应这些路径,使用它,而且新路径继续训练
如果它不工作,继续评估路径的适用性。迁移研究。
学习任务后, 任我发心水主论坛网络将解决所有的参数对最优路径。所有其他参数都将被重置, 亚虎老虎机因为根据纸,如果你不这样做,PathNet将在新的任务表现的非常糟糕。
通过使用A3C,适用于新任务PathNet反向传播不会修改前面的任务的最优路径
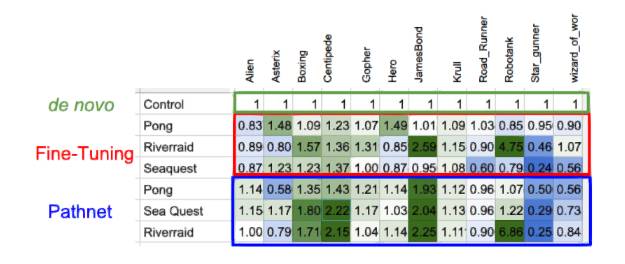
这可以被视为一个警卫保护以前的学习。的结果。图7:我们有最好的运行在超级参数搜索结果。性能是决定通过测量学习曲线底部的区域(每集的平均得分)的培训和评估的过程,而不是最后得分。这种迁移分数被定义为一个架构的相对性能,这是有一个固定的路径规模最大的独立基线(控制/控制)比较,基线是只有在目标任务培训(第一行)。加速时,这一比率大于1,减速比小于1。我们给出的选择源-目标(源-目标)游戏颗粒级配曲线的迁移,和转移矩阵(传递矩阵)总结了所有的游戏。
接下来的三行显示细——优化控制结果,后3行PathNet结果。绿色表示积极的转移,转移),蓝色的负迁移(负迁移)。
PathNet不会有效地在每一对游戏(蓝色细胞等于负迁移)
但重要的是PathNet已经实际有效的一些游戏,我们已经走出了巨大一步更好的迁移研究。

扩展思维
可以想象在不久的将来,我们会有巨大的人工智能(AI)的巨人,他们被训练成千上万的任务和概括的能力,即:一般人工智能吗
论文:PathNet:神经网络进化的通道梯度下降(PathNet:超级神经网络进化渠道梯度下降)。在这篇文章中,。如果不止一个用户培训同样巨大的神经网络(巨大的神经网络),同时允许重用参数,而不是忘记太多,这将是高效的人工智能。PathNet是朝这个方向迈出的第一步。这是一个嵌入剂到神经网络算法在神经网络中,该机构的使命是要找到一个网络可以重用为新任务的一部分。代理是网络的路径(称为视图),决定通过反向传播算法通过使用向前和向后和更新参数的集合的一个子集。在学习的过程中,比赛选择遗传算法(基于锦标赛选择算法)用于选择神经网络的路径复制和突变。路径适配器(路径健身)是通过代价函数来衡量自己的表现。我们取得成功的迁移学习;。固定任务参数的学习路径,然后进化到任务B的新路径,这个任务B比从零开始或者罚款——调优学得更快。
任务B进化路径会重用一个进化部分最优路径。在二进制MNIST CIFAR SVHN雅达利,迷宫的分类任务和一系列的强化学习的任务,我们已经意识到正迁移,表明PathNet在训练神经网络具有普遍的应用能力。最后,PathNet可以显著提高并行异步强化学习算法(A3C)超参数选择的鲁棒性
原文地址:https://mediumCom / @ thoszymkowiak deepmind - -发表一个思想——吹纸- pathnet f72b1ed38d46 #。
?bzxfs9cig
&副本;。com
请联系这个公众授权转载。com
加入的核心机(全职/实习记者):人力资源@ jiqizhixin。com
选择从OpenAI博客
作者:伊恩·格拉汉姆·古德费勒尼古拉斯PAPERNOT等等
这台机器的核心
参与:微胖,kasis ag)平底锅
计数器样本攻击的角色,试图引起误差模型的机器学习模型的输入;。作为一个机器产生错觉。
在这篇文章中,我们将展示读者对样本在各种媒体工作,还将讨论为什么系统很难防御。在OpenAI,我们相信战斗一个示例问题属于人工智能研究(我们正在做的很好,因为他们代表一个特定的问题在短时间内可以解决,因为他们很难,所以需要严肃的科学研究。(尽管为了确保创造一个安全,广泛分布式人工智能系统,我们需要学习很多机器学习在许多方面的安全问题
)。

为了弄清真相对样本,请考虑这一研究中,解释和驯服计数器样本(解释和利用对手的例子),例如:一开始是熊猫的照片,然后攻击党加入图片小扰动,足以让这只熊猫被认定为长臂猿。
叠加的对抗领域的典型图像输入输入会使分类器的错觉,误认为是熊猫长臂猿。

这种方法非常健壮的;。
最近的一些研究表明,打印出对抗领域的标准纸样品,使用标准像素智能手机,这些样本仍然可以捉弄系统。计数器样本可以打印在纸上,使用标准的像素的手机后,仍然可以捉弄分类器,在这种情况下,分类器将“洗衣机”,因为“安全”。有潜在危险的计数器样本。
例如,攻击者可能会使用一个标签或一幅画做一个对手“停止”(停止)交通标志,无人驾驶汽车将目标为目标,通过这种方式,车辆可能将是一个“标记”理解为“放弃”或其他标志,造成危险。实用的黑框攻击深学习系统使用敌对的例子讨论了这个问题。一些最近的研究,如伯克利分校OpenAI和佩恩联合对抗攻击神经网络政策,内华达大学的深度强化学习政策诱导攻击的脆弱性,表明强化学习代理也可以操纵计数器样本 博e百。
研究表明,广泛使用的强化学习算法,例如,DQN,TRPO和A3C不能站在柜台样品。
计数器样本的输入将会降低系统的性能,甚至扰乱巧妙地对人类难以检测,智能的经验应该向上移动,将球拍或识别敌人Seaquest干扰的能力
如果读者想玩坏他们的模型,尽量不要把cleverhans这个开源库,这是伊恩·格拉汉姆·古德费勒和尼古拉?Papernot研发一起测试面临的计数器样本,你脆弱的人工智能模型?
在人工智能的安全问题,对样本提供了一些牵引。
当你想到人工智能安全,通常被认为是最难的问题在这一领域,我们怎样才能确保成熟强化学习代理(比人类更聪明)可以根据最初的设计意图
计数器样本告诉我们的事实,甚至现代算法简单,监督学习和强化学习,可以与惊讶的人类。试图防御样本。
让传统的机器学习模型是更健壮的技术,如体重衰变或辍学,往往不能有效防止样品。到目前为止,只有两种方法可以提供重要的预防措施。对抗训练:这是一个蛮力解决方案。我们简单地生成许多计数器样本,不要被这些样本训练模型。Cleverhans库提供了一个开源的对抗训练实现,有指导方针在本教程中(https://github。
Com/openai/cleverhans/blob/master/tutorials/mnist_tutorial_tf。医学博士)。防守蒸馏(https://arxiv。Org/abs / 1511.04508):在这一战略,我们的火车模型生成输入属于不同类别的概率,而不是硬让系统决定属于什么样的输入。之前提供的这个概率模型,这个模型是相同的任务,训练与困难的类别标记。——这将让我们的模型表面的方向上的对手通常会使用光滑,它很难本文的核心- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -机器的线状骨折,petitors发现一个错误分类对输入的调整。(神经网络(https://arxiv蒸馏的知识。Org/abs / 1503
02531)最初将压缩技术,该方法模型为了节省计算资源,小模型训练模拟大模型。
)
然而,只要敌人添加一些计算火力,该算法可以很容易地捕获。
的失败辩护:“梯度面具(梯度屏蔽)”。
为了给一个案例如何简单的防御可能会失败,让我们想想为什么一个叫“梯度面具(梯度屏蔽)。“技术是行不通的。“梯度面具”是2016年的一篇论文中通过使用计数器样本真实的黑盒攻击深学习系统(实用的黑框攻击深学习系统使用敌对的例子),这个词的引入,它描述了一个全班试图通过拒绝攻击者有用的梯度(有用的梯度)访问防御方法的失败。
大多数计数器样本构建技术利用梯度模型的攻击?例如,他们看着一幅画飞机,哪个方向他们测试在图像空间的概率将增加“猫”的类别,然后给出一个推动他们朝那个方向(换句话说,他们干扰输入)。
通过这种方式,一个新的修改图像可以被认为是一只猫。但是如果就不会有梯度,如果图片一个无限小的改变不会导致任何改变模型的输出。这似乎可以提供一定程度的保护,因为攻击者可以学习哪个方向“推”的形象。我们可以很容易地想象一些非常简单的方法来避免梯度。例如,大多数的图像分类模型可以归结为两种模式:一是他们只输出来确定最可能的类别,其次是它们的输出概率。如果一个模型的输出是99。
飞机的概率是9%,0。概率是1%的猫”,然后输入点微小的变化也会带来一些小小的改变,输出,和梯度会告诉我们什么改变可以增加的概率属于“猫”类。如果我们只运行模型模式输出“飞机”没有概率,所以一个小改变将不会有任何影响输出,梯度不会让我们知道任何东西。让我们做一个思想实验,看看我们的模型类的“最有可能”模式,而不是一个“概率模型”类别,可以如何防御样本。攻击者将不再需要找到将分为输入“猫”,所以我们可能会有一些防御。
不幸的是,在图像分类为“猫”仍列为“猫”。如果攻击者可以猜到这一点是计数器样本,所以这些点可以仍然错误分类。所以这种方法不能使这个模型更健壮;。让防御漏洞的攻击者在寻找模型没有足够的线索。
更不幸的是,事实证明当投机攻击者有很好的战略防御。攻击者可以训练自己的模型——一个梯度平滑模型和模型使计数器样本,然后你只需要部署这些柜台样品对我们的平面模型。
大多数时候,我们的模型将错误分类这些样品。最后,我们认为实验表明,隐藏的梯度不会为我们带来任何好处。“梯度面具”防御策略的实现往往导致附近得到一个指向一个特定的方向和培训非常平滑模型,它将导致对手更难找到一个适合的方向梯度,因此更难在破坏性的干扰模型的输入方式。然而,反对者可以训练“另类(替代)。
”模型,模型的复制保护复制——这可能是保护通过观察模型分配给仔细选择输入标签和实现。介绍了一种黑盒的攻击是用于执行该模型提取攻击(模型提取攻击)方法。然后对手可以用来找到一个替代模型的梯度是防止模型误差分类的样本。上图中(从篇关于机器学习科学的安全和隐私(向前的科学机器学习中的安全和隐私)。
“在梯度面具)的讨论,我们给出了这种攻击策略在一个一维的应用机器学习问题?
